B+树 与 LSM树
引言
我们大家都知道,在MySQL的InnodeDB中索引采用的是B+树。在所有加速查询的存储领域,B+树都大展身手。然而LSM树,由于能够加速写操作,所以在存储等要求高性能高并发写操作的场景,LSM在这个领域有着不可替代的地位。
每一个数据结构都有着自己的特点,没有万能的架构能够解决所有场景的问题。因此B+与LSM树都只能在自己擅长的领域带来更好的作用。当然万物皆有两面性,能解决问题的同时,肯定也会在其他方面带来一定的问题,只是这些问题对于某些场景,并不是那么严重或者可以接受。
那这两个数据结构,之间是否有什么关系呢?区别是什么样子的?
B树
平衡树是一种平衡的查找树,而任何一种平衡树的查询复杂度都和平衡树的层高有关系,层高越低,查询的效率越高。而B树就是一种层数相对较低的平衡树。
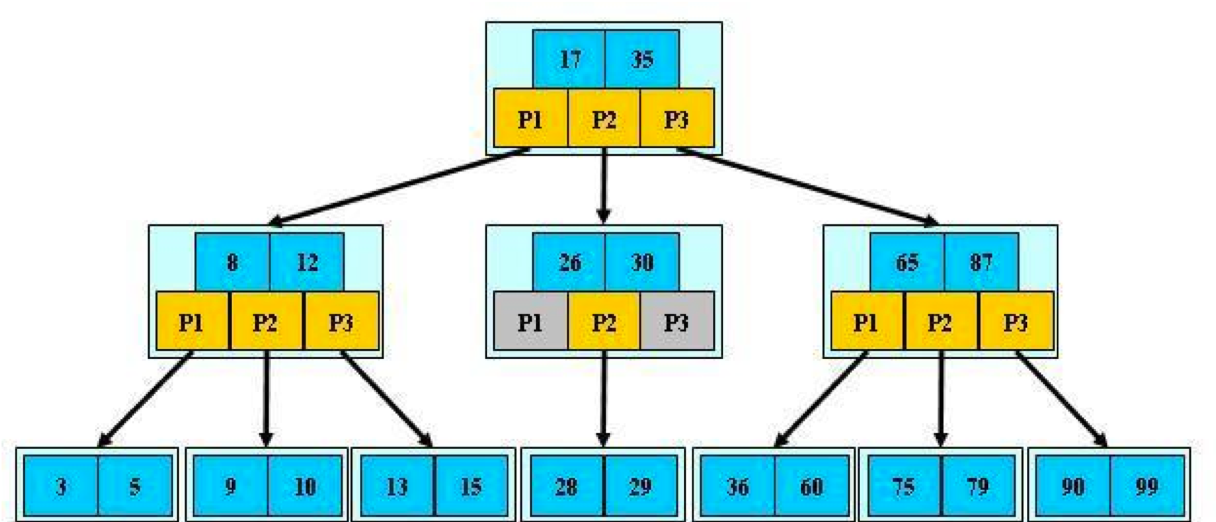
B树的特征如下:
- 是一个平衡树
- 根节点至少有两个子节点
- 每个节点有M-1个Key,并且以升序排序
- 位于M-1和M key的子节点的值位于M-1和M key对应的Value之间
- 其它节点至少有M/2个子节点
- 所有叶子结点位于同一层(叶子结点指的是最下层NULL的结点)
可以看出,在每个节点上都会存储数据的本身,由于计算机操作系统的存储是以页的方式组织。每次查询一个节点,就需要进行一次I/O操作。因此树的高度越低,I/O操作越少。而B树的层高与操作系统页的大小有关系,页越大,则B树的高度越低。
B+树
B树如果需要更加降低高度,就需要跟随着硬件与操作系统的发展。但这个发展并不是那么快,那么怎么更加降低高度呢?降低高度等于每一页中存储的数据量更多。因此提出B+树,提出内部节点只存储索引,不存储数据,因此内部节点可以在同样的空间中存储更多的数据,因此降低树的高度。
B+树的特征如下:
- 继承于B树的特征
- B+树内部节点部保存数据,只作索引作用,叶子节点才保存数据
- B+树相邻的叶子节点之间通过链表指针连起来,形成链表
- B树中任何一个关键字有且只会出现在一个节点中,而B+树中可以出现多次
- B+树的查找,如果可以查找到,会查询到叶子节点中
树的高度进一步降低了,但是如果在B+树中存储大的数据,依旧会受限于操作系统页大小的限制。因为一页中存储的数据依旧是有限的,如果每一个叶子节点存储的数据量变小,因此节点数会因此增多,从而数的高度增加。因此提出了将数据与B+树分离的存储方式。即只在B+树的叶子节点中存储索引,数据存储在索引指向的页中。
B-Link树
B-Link树是对于B/B+树的优化,核心思想是:
- 在中间节点增加字段link pointer,指向右兄弟节点,B-link Tree的名字也由此而来
- 在每个节点内增加一个字段high key,在查询时如果目标值超过该节点的high key,就需要循着link pointer继续往后继节点查找
BLink树为了解决的是为了并发控制,读操作会判断子节点的右兄弟节点的最小值是否大于它正在查找的目标键值,如果不是说明目标键值对在右兄弟节点或者更右边的节点,指针就会往右走,直到找到某个右兄弟节点的最小值大于目标键值。因此可以保证在节点分裂时,依然可以进行读操作。这种思想其实在Redis的map以及ConcurrentHashMap扩容时,有类似的思想。
参考:
LSM树
从上面B树和B+树可以看出,都是为了加速读操作。但是在进行写操作时,需要先在树上进行索引,然后更新数据。因此写操作的复杂度会在写操作上更加复杂。但读操作可以使用大内存或者大缓存的方式进行加速,而写操作必须要写入到磁盘中才能认为写成功。
因此不管如何如何加速查询操作,但是在进行写操作时,比如更新B/B+树的数据的时候,会受限于磁盘的写入性能。但我们都知道磁盘的随机写性能,和顺序写性能,差距有着好几倍。因此要加速写性能的本质是充分利用磁盘的顺序写,减少随机写。
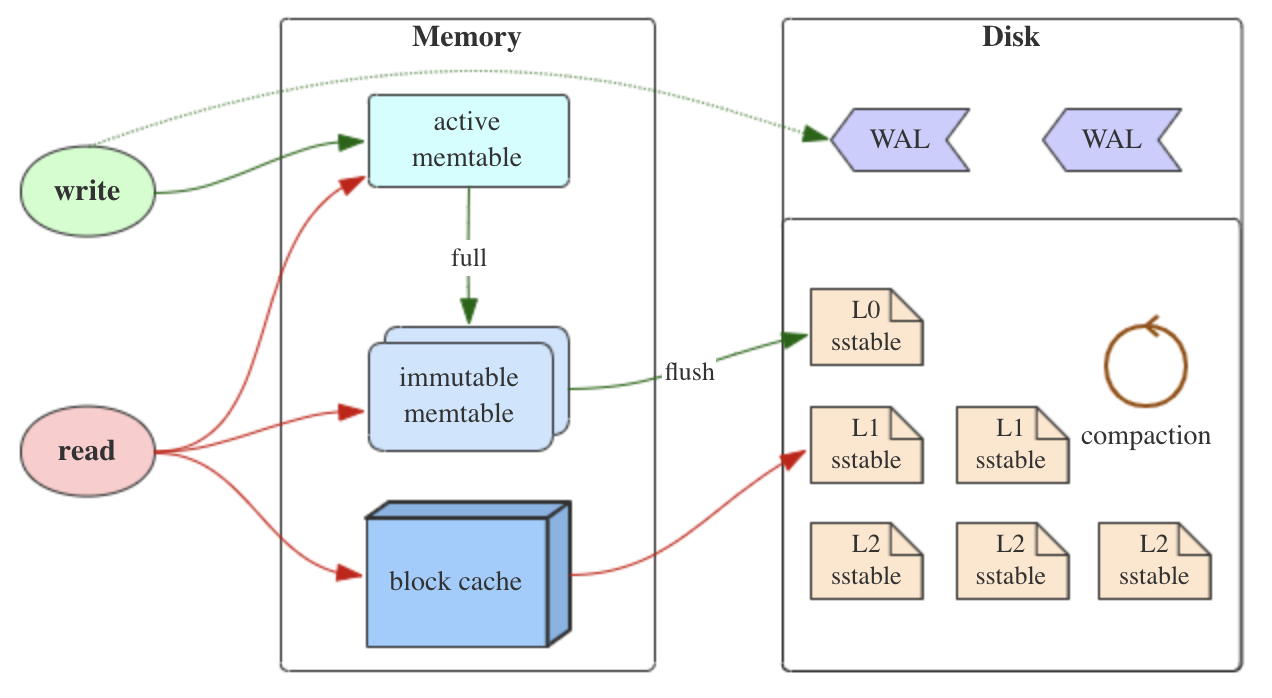
LSM树的特征如下:将磁盘的随机写转化为顺序写来提高写性能,但付出的代价就是牺牲部分读性能、写放大(B+树同样有写放大的问题)
- 是一个横跨内存和磁盘的,包含多颗“子树”的一个“森林”
- 分为level0,level1……level n多颗子树,只有level0在内存中,其余level0在内存中,其余level 1-n在磁盘中
- 内存中的level0子树一般采用排序树(红黑树/AVL树)、跳表或者TreeMap等这类有序的数据结构,方便后续顺序写磁盘
- 磁盘中的level 1-n子树,本质是数据排好序后顺序写到磁盘上的文件,只是叫做树而已
- 每一层的子树都有一个阈值大小,达到阈值后会进行合并,合并结果写入下一层
- 只有内存中的数据允许原地更新,磁盘上数据的变更只允许追加写,不做原地更新
参考来源于RocksDB的存储架构图:
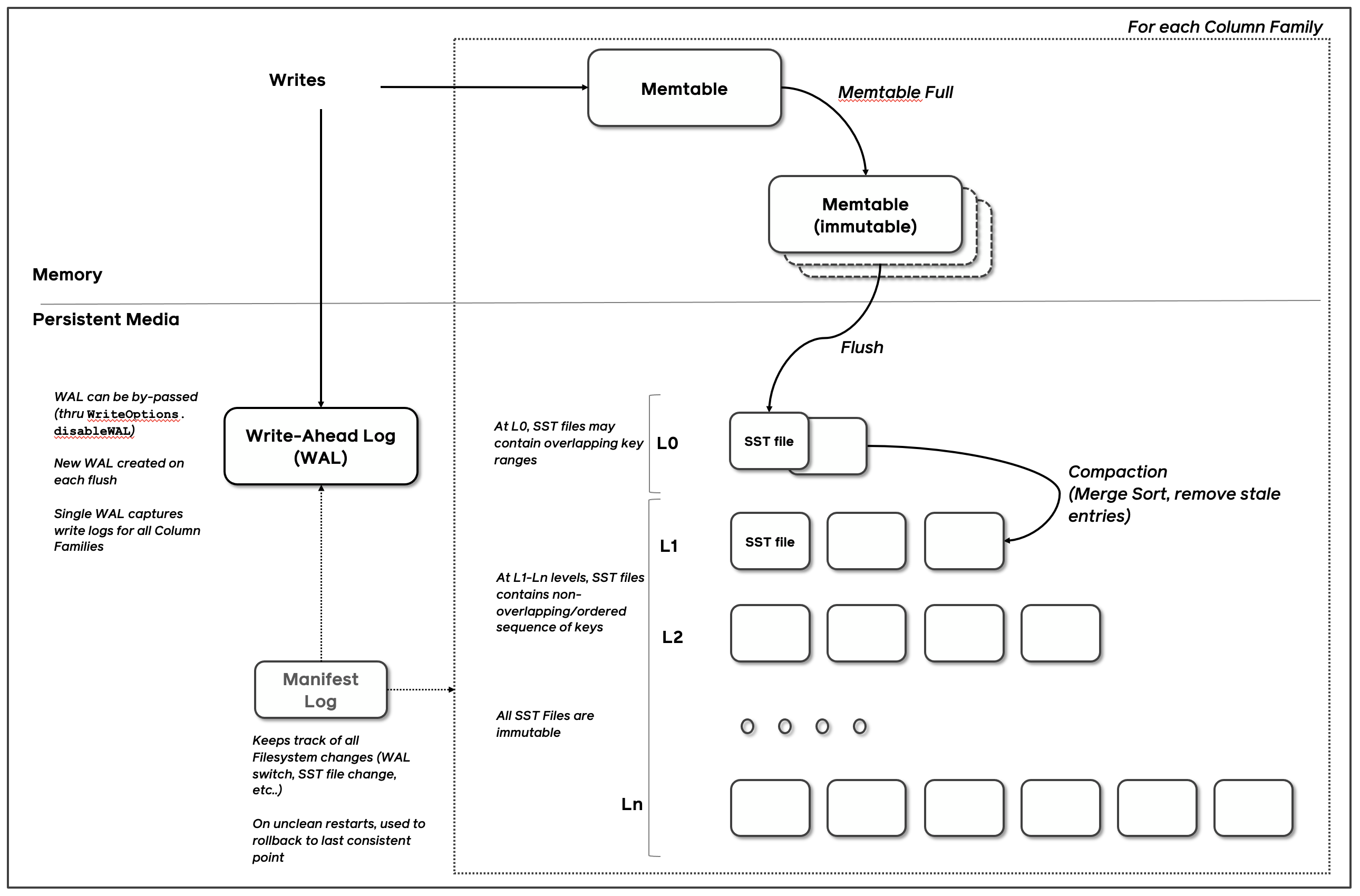
在实现的时候,比如LevelDB、RocksDB实现时。会先写入到内存的Memtable,当Memtable满了之后,则标记为immutable,不再允许写入,重写新建一个Memtable写入。定期将immutable memtable 刷入到磁盘中,写入到L0层。内存中的Memtable和L0层都是没有排序的,因此在查询时,都需要从头开始遍历。后台线程定期将L0层合并写入到L1层,以及不断的从上层合并写入到下层。
在写操作时,会直接写入WAL文件中,然后在进行写操作,这样保证数据不会丢失。
内存的Memtable和L0层的数据,不管是更新或者删除,都是直接append写入。因此一个数据在LSM中可能会有多个版本的数据同时存在。
参考:
- https://zhuanlan.zhihu.com/p/415799237
- https://github.com/facebook/rocksdb/wiki/RocksDB-Overview
- http://mysql.taobao.org/monthly/2018/11/01/
- https://developer.aliyun.com/article/758369
BW树
Bw树提示,结合了两大存储引擎B+树和LSM树的特点。
主要做了2个优化:
- 通过无锁的方式来操作B+树,提升随机读和范围读的性能。核心的思想是把B+树的page通过page id(PID)映射map,map的[key, value]变成[PID, page value],把直接对page的修改,变成一个修改的操作记录,加入到“page value”,所以“page value”可能是一个“base page”即page原始的内容,和一串对page修改形成的记录的链表,而在修改记录链表中加入一个修改记录节点可以很容易变成一个无锁的方式来实现。另外就是对B+树的split和merge操作也通过类似的原理,把具体的操作细化成好几个原子操作,避免传统的加锁方式。
- 把传统checkpoint刷page的变成通过Log-Structure Store方式刷盘,把随机写变成顺序写,提高写的性能。
主要特点有:
- 总体分三层:索引层,缓存控制层和Flash存储层
- 整体上是一个棵B+树,同时借鉴了B-link树的思想,每个节点存在一个指向右兄弟的指针
- 在单独树节点上表现为类似LSM树的Log-Structure,每个逻辑节点由a base node + a delta records chain组成
- 实现latch-free的核心数据结构叫Mapping Table,通过CAS进行installing操作,修改一个mapping entry可以同时完全多个逻辑指针的修改
- flash层也是用Log-Structure Store(append only)对逻辑页的物理存储(base page和delta record)进行管理
参考: