ConcurrentHashMap 源码分析(Java version 1.8)
在我之前的文章《HashMap 源码分析》中分析了HashMap的源码,众所周知,ConcurrentHashMap是线程安全的Map,在Java 1.7及以前版本使用分段加锁机制,而1.8版本开始使用CAS操作,抛弃了segment,并只对哈希桶数组的的单个元素加锁。相对于HashTable对于每个方法都使用synchronized,效率提升了非常大。
本文所解读的ConcurrentHashMap是基于Java 1.8 版本。部分代码过于繁琐,因此建议对照源码阅读。
总体结构
从总体上,ConcurrentHashMap与HashMap的结构是相同的,是基于哈希桶数组加链表以及红黑树构成的。
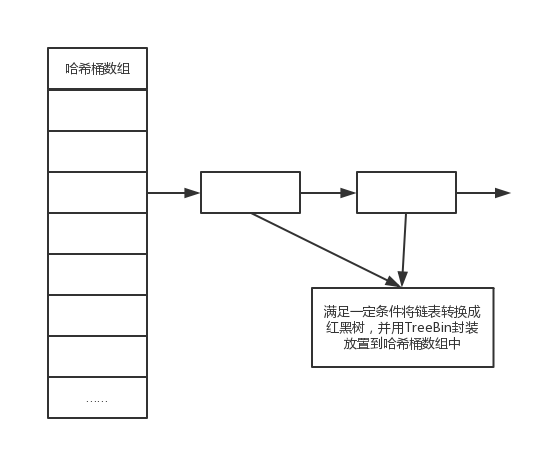
红黑树,是平衡查找树的一种,使用这种结构,可以加速查找。
CAS操作,是一种乐观锁技术,直接CPU支持,通过不断的尝试,获取值并进行比较操作,这种操作相比较锁来说,减少了不少的消耗以及等待等。
<<:左移,相当于乘以2
>>:右移:相当于除以2
>>>:无符号右移,空位补0
节点
在节点上,也是基本与HashMap相同,有Node,并通过继承等,得到TreeNode、TreeBin、ForwardingNode等类。
ForwardingNode用来标示当前节点在扩容的时候已经迁移到新的哈希桶数组中了,当前的hash为-1,而TreeNode是构建红黑树的元素,而在哈希桶数组中存储的却不是TreeNode,当红黑树时,使用TreeBin封装TreeNode后放入哈希桶数组,这点与HashMap不同。
1 | static class Node<K,V> implements Map.Entry<K,V> { |
而ForwardingNode相对与Node来说,多了一个nextTable属性,创建该Node时,除了将hash设置为-1外,还需要将nextTable设置成指向扩容后哈希桶数组的引用。
1 | static final class ForwardingNode<K,V> extends Node<K,V> { |
TreeNode中继承了Node的属性,也实现了指向父节点,左右节点,以及前一个节点的引用。而在TreeBin中,需要关注的是first,是指向红黑树根节点的的引用,而用lockState来对红黑树加读写锁。
1 | static final class TreeNode<K,V> extends Node<K,V> { |
构造函数
在构造函数中,与HashMap比较相似,只是初始化一些变量的值,如初始化容量、负载因子等,以及concurrencyLevel,这个在1.8版本中已经不重要了,初始化容量可能会受这个元素影响。
1 | public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { |
当然,这个与HashMap中非常相似,在初始化哈希桶数组容量时,会使用tableSizeFor()将数组长度初始化为2的n次方的长度。而负载因子是指在符合一定条件下,当目前的元素总数达到负载因子乘上容量时,将进行扩容操作。
get
在说明get方法前,需要注意在ConcurrentHashMap中,所有传入的key、value等都不能为null,否则会抛出NullPointException。
首先,对应HashMap中的hash()函数的speed函数,相对于来说增加了按位与上0x7fffffff,这个为2进制中从右到左31个1。保证了hash值一定大于0,这个因为在ConcurrentHashMap中,为负数的部分hash是有特殊含义的,这个在后面会有提到。
1 | static final int spread(int h) { |
在get中,首先根据key计算hash,然后使用哈希桶数组长度n得到的n-1值按位与上hash,得到定位到哈希桶数组中的位置;然后使用原子操作,取得这个位置的Node;如果当前的hash值相等,并且key相等,直接返回val;如果当前值的哈希小于0,则表示当前的Node要么是TreeBin,或者ForwardingNode,然后调用其find()函数查找。其他情况下,即链表情况,遍历链表返回结果。
1 | public V get(Object key) { |
其中find会根据Node不同调用各自的find函数。
首先是ForwardingNode的find函数,首先,在这个Node的情况下,表示当前Node的值已经迁移到了新的哈希桶数组中,因此在查找时,也需要进入新的哈希桶数组中查找。循环尝试nextTale中定位hash位置。通过Node或者TreeBin查找节点。具体代码如下,其中保证了扩容后的哈希桶数组又出现扩容等情况,通过不停对于每个数组尝试操作。
1 | Node<K,V> find(int h, Object k) { |
而对于TreeBin的find,在每次循环中,先判断当前是否已经进入写锁(即存在写的线程或者等待写的线程),如果是,则判断当前节点的hash以及key相等,则直接返回当前节点,否则则进入下一个节点(在TreeNode中也又Node的元素,因此每个节点依然有指向下一个节点的引用);当前没有写锁的情况下,使用CAS操作给TreeBin加上读锁,并查找Node,并在finally中,判断如果将读锁去掉一个读锁后,不存在正在写的线程,则唤醒正在等待写的线程。
1 | final Node<K,V> find(int h, Object k) { |
put
put操作中,与HashMap有所不同,此处不支持value为null。
整个put操作分为几个部分,计算位置,判断哈希桶状态是否需要加入帮助扩容,放入节点,判断是否需要红黑树化。首先计算哈希值以及一些准备状态,比较简单。需要说明的是binCount在这儿代表着的是当前链表的长度,当已经是红黑树时,直接赋值2。然后进入循环尝试put操作中。
1、当哈希桶数组不存在时,初始化数组
当进入初始化函数后,将会去循环尝试,循环里先判断sizeCtl是否已经小于0,表示已经有其他线程进入了初始化的环节了,因此自旋等待;其他情况则尝试将sizeCtl置为-1,然后初始化一个哈希桶数组,最后将sizeCtl置为数组长度乘上负载因子。
需要注意的是,Thread.yield();是将当前线程从运行态放入就绪状态的队列,一旦抢到cpu就可以继续执行。并且这里是循环里执行的,只要没有进入put完成,就会一只循环去尝试put。
2、当hash值散列到数组上位置为空时,尝试cas操作去直接put,成功则退出。
3、当哈希桶数组对应位置上的值已经迁移到新的哈希桶数组时,即hash为-1,则帮助扩容。扩容相关后续详解。
4、其他情况,表示当前节点有值,形成链表或者红黑树。
首先在该节点上加锁,并再次校验hash对应的是该数组位置。当为链表时,直接将Node放了进去,注意重复key存在的情况会根据onlyIfAbsent判断是否更新,并且循环链表时,需要给binCount自增。
如果是红黑树的情况,直接将binCount设置成2,使用putTreeVal函数放入新节点或者拿到老节点,同样根据onlyIfAbsent更新新的val。
在加锁结束后根据binCount是否大于等于8来判断是否需要进行红黑树化。同样的,进行红黑树化时,也需要对数组中的该节点进行加锁操作。
1 | final V putVal(K key, V value, boolean onlyIfAbsent) { |
当然,在最后循环尝试结束后,将总数加1。
在增加数量时,会有根据check来判断是否需要扩容,@param check if <0, don't check resize, if <= 1 only check if uncontended。
addCount的基本逻辑如下。
1、尝试使用cas修改baseCount。
2、如果修改失败,则随机取CounterCell数组的一个元素更新数据。
3、如果数组为空或者更新失败则调用fullAddCount函数,进行循环插入插入数据。此处包括对应CounterCell数组的一系列扩容操作。
4、如果需要check,则调用sumCount函数计算总数,根据情况扩容。
当然分别有扩容的初始化数组主线程以及帮助扩容的其他线程,根据sizeCtl的值进行判断。
sumCount的计算,是将baseCount的值与数组中的所有值累计。
扩容
扩容是ConcurrentHashMap中非常重要的操作,类似在HashMap中相同,扩容的基本操作都是将哈希桶数组的长度扩展成两倍,然后将当前桶中的节点依次迁移到新的桶的。同样的,在迁移的时候,只需要将节点迁移到新的哈希桶的数组中的相对位置以及右移当前数组长度的位置。
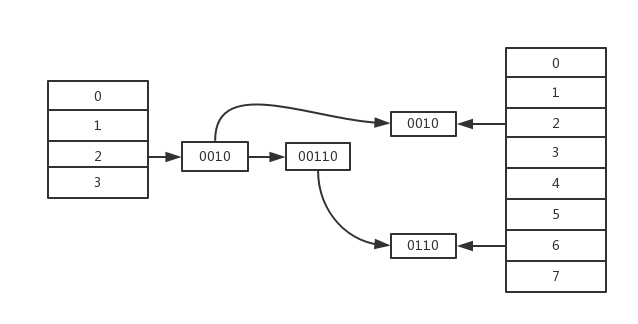
首先,在什么时候可以进入扩容操作呢?1、当在每次put的addCount时,map的节点数量达到扩容的负载的限制时,则进行扩容;2、当put时候判断已经进行扩容的时候,则进入帮助扩容;3、当进行清除的时候,正在扩容也进入帮助扩容;当在替换节点时,(删除记做替换节点为null)的情况下,如果哈希桶数组在扩容也进入帮助扩容。
1、扩容开始时,首先计算每个线程需要迁移的哈希桶数组的元素,最少16,此处充分利用了cpu的并发粒度,计算同时并发时每个线程需要负责的数目。
2、当扩容后的迁移哈希桶数组不存在的时候,尝试创建哈希桶数组。
3、构建ForwardingNode指向新的哈希桶数组。
4、循环中去申请扩容负责的部分,以及进行扩容。在这里面advance代表是否进入迁移下一个节点,而finishing代表是否以及完成了当前分配负责区域的迁移。
5、循环尝试使用cas操作分配迁移的的数组的索引下标,advance设置成true,进入迁移操作。
6、判断分配阈值超过范围。根据finishing判断结束,则更新一些变量(此处对于一次扩容只会执行一次);其他情况,则将sizeCtl减1成功,表示有新的线程完成了扩容操作,然后通过(sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT筛选出最后一个线程设置finishing为true进入扩容的最后操作,即上述说的进行变量更新操作(这儿保证了只有一个线程进行该操作)。最后一个线程将循环哈希桶数组进行再次校验所有的节点已将迁移完成。
7、如果当前需要迁移的数组元素为null,则直接使用cas设置为ForwardingNode,设置成功则前进。
8、如果当前正在迁移,即hash为-1,则直接前进。
9、当前哈希桶数组元素存储的是链表或者红黑树。对node进行加锁并再次校验。在这种情况下,当然依然需要对链表、红黑树进行分别的处理。
首先是链表的情况,这种情况下,拆分成两个链表也不会出发红黑树化的操作。先得到迁移相对位置或者偏移位置的某一种情况的最后一个节点,即最后一个与前一节点迁移位置不同的节点,即在这个节点之后的节点都会迁移到相同的位置。
并根据这个节点是否需要迁移,将节点赋值给ln或者hn,前者是迁移到相对位置,后者迁移到偏移位置。循环链表构建两个数组,链表只需用循环到上述所得最后一个与前一个节点迁移位置不同的节点即可。最后将两个链表写入新的链表的对应位置,然后将当前哈希桶数组的值设置成ForwardingNode,表示已经完成扩容。
为什么需要先进行定位到最后不需用循环做构建新链表的,然后再循环到该节点呢构建链表呢?这点上我暂时没有明白,毕竟一个链表的最大长度也就7的长度,不管怎么做,其效率都是非常高的,而且不会出现特别慢的情况。
另一种情况就是红黑树的情况。这种情况下依然需要构建两个红黑树,当然最开始构建的时候是构建两个TreeNode的链表,当然同时需要记录每个链表的节点数。最后根据计数结果判断是构建红黑树还是链表化。构建红黑树的时候是在TreeBin的构造函数。然后设置新的哈希桶数组的值,最后前进。
最后循环进入下一个需要迁移的位置。
在上诉说的第6点中提到了sizeCtl的值通过标记的移位等操作判断是最后一个执行的线程。相关代码如下。
1 | ... |
这部分中容易受到sizeCtl注释中的影响,注释中如下,说明有负的(1+n)时代表有n个线程在帮助扩容,在我的理解下这儿的注释是错误的。
When negative, the table is being initialized or resized: -1 for initialization, else -(1 + the number of active resizing threads).
我的理解下,sizeCtl在进入的扩容的第一个线程时,声明为一个负得很大的数,比如当一个容量为64的map扩容时,这个sizeCtl在第一个线程进入扩容后的值为-2145845246。然后在每个线程进入扩容后,会将这个sizeCtl加1,然后每次线程结束扩容后将sizeCtl减1。所以当前正在扩容的线程应该是(resizeStamp(tab.length()) << RESIZE_STAMP_SHIFT) + 2 - sizeCtl + 1。至于为什么要这么写来表示扩容呢?这点上我不是很清楚。在下面代码中表示了每个进入扩容的函数都会经历的部分相似逻辑。
1 | ... |
其中表示了当已经进入扩容的情况下,当前线程加入后线程线程数限制resizeStamp + (1 << (32 - 16)) - 1),需要校验如果扩容分配的空间已经分配完成,如果满足这些条件下,则线程退出不进入扩容,否则将sizeCtl加1,进入扩容。如果没有线程进入扩容,则将sizeCtl初始化,然后进入扩容。
replaceNode
为什么要特别提及replaceNode函数呢?replaceNode函数不仅仅在replace的时候使用了,而且在remove的时候也调用了,只是传入的value为null。
依旧,首先计算哈希值,然后循环尝试。
1、当数组不存在或者哈希定位的值不存在时,结束。
2、如果当前位置已经扩容,代表当前map进入扩容操作,则帮助进行扩容。
3、其他情况,即当前位置存在链表或者红黑树等。这种情况下,会将当前节点加锁,并进行再次校验验证。
当前是链表的情况,循环找到key对应的节点,如果需要更新的value是null的情况,则删除节点,否则替代节点。(首节点的情况下,需要单独处理,将首节点的Node设置到哈希桶数组中。)
红黑树的情况,使用TreeNode的findTreeNode函数返回对应的节点,value不为null的情况,更新value或者使用removeTreeNode删除节点。删除情况通过removeTreeNode返回true/false结果判断是否进行红黑树化。
4、在循环尝试结束后,判断是否删除以及是否成功等,将map的节点数减1。
clear
clear的意思是移除map中的所有的node,当然依然是循环哈希桶数组中的每个元素,做去除操作。每个循环里定位到当前节点。
1、如果当前节点为空的情况,直接进入下一个节点。
2、当前节点的hash为-1时,表示当前节点以及迁移到新的哈希桶数组,则进行帮助扩容操作,并将需要clear的哈希桶数组修改为扩容后的数组,并将清除索引修改为0,扩容后重新进行清除操作。
3、其他情况,即当前节点存在链表或红黑树的情况。先给节点加锁,然后获取链表的开始节点,TreeNode的情况下也有指向下一个Node的引用,开始节点为TreeBin的first指向的节点。
循环链表,累计Node的数目。然后将当前哈希桶数组的节点置为null。
1 | public void clear() { |
在循环清理完成后,调用addCount函数将map中的总数减掉清除的Node数目。
附
compute是传入function来计算新值,然后put(前提是符合条件,才进入计算新值)。以及merge等函数等。
以及在1.8版本后推出使用mappingCount()来代替size函数。
ConcurrentHashMap是支持并发的Map,并且尽量减少来加锁的操作以及减小了加锁的粒度,并使用了CAS操作,因而增大了并发度。
对于其中一些设计及写法的原因,目前还很迷糊。